Here is the implementation of Cosine similarity of two vectors (vec1,vec2) using java
------------------------------------------------------------------------------------------
public class cosine {
public static void main(String[] args) {
int vec1[] = {1,2,5,0,2,3};
int vec2[] = {2,1,3,2,0,1};
double cos_sim = cosine_similarity(vec1,vec2);
System.out.println("Cosine Similarity="+cos_sim);
}
private static double cosine_similarity(int[] vec1, int[] vec2) {
double dp = dot_product(vec1,vec2);
double magnitudeA = find_magnitude(vec1);
double magnitudeB = find_magnitude(vec2);
return (dp)/(magnitudeA*magnitudeB);
}
private static double find_magnitude(int[] vec) {
double sum_mag=0;
for(int i=0;i<vec.length;i++)
{
sum_mag = sum_mag + vec[i]*vec[i];
}
return Math.sqrt(sum_mag);
}
private static double dot_product(int[] vec1, int[] vec2) {
double sum=0;
for(int i=0;i<vec1.length;i++)
{
sum = sum + vec1[i]*vec2[i];
}
return sum;
}
}
Tuesday, March 26, 2013
Cosine similarity and vector space model
Vector
space model :The representation of a set of documents as vectors in a
common vector space is known as the vector space model and is
fundamental to a host of information retrieval operations
ranging from scoring documents on a query, document classification and
document clustering.
The
set of documents in a collection then may be viewed as a set of
vectors in a vector space, in which there is one axis for each term.
Cosine
Similarity :
To
quantify the similarity between two documents in the vector space ,we
have different approaches.The first one is to find the magnitude
difference between the document vectors.But this approach has a
drawback like if one document is very large than the other,then the
difference will be large even though they have similar contents.
To
overcome this drawback,the second approach is finding the cosine
similarity which compensates the document length.
The
cosine of two vectors can be easily derived by using the Euclidean
dot product formula:
a.b
= ||a||||b|| cosΘ
cos_sim(d1,d2)
= v(d1).v(d2)/||v(d1)|| ||v(d2)||
For
text matching, the attribute vectors A
and B
are usually the term frequency vectors of the documents. The cosine
similarity can be seen as a method of normalizing document length
during comparison.
In
the case of information retrieval the cosine similarity of two
documents will range from 0 to 1, since the term frequencies (tf-idf
weights) cannot be negative.
Let's
consider the following example,
Document1
- Gilbert: 3
- Hurricane: 2
- Rains: 1
- Storm: 2
- Winds: 2
Document2
- Gilbert: 2
- Hurricane: 1
- Rains: 0
- Storm: 1
- Winds: 2
We
want to know how similar these documents are, purely in terms of word
counts (and ignoring word order).
The
two vectors are, again:
a:
[3,2,1,2,2]
b:
[2,1,0,1,2]
The
cosine of the angle between them is about 0.9439.
By
measuring the angle between the vectors, we can get a good idea of
their similarity , and, to make things even easier, by taking the
Cosine of this angle, we have a nice 0 to 1 (or -1 to 1, depending
what and how we account for) value that is indicative of this
similarity. The smaller the angle, the bigger (closer to 1) the
cosine value, and also the bigger the similarity.This
gives us a great similarity metric with higher values meaning more
similar and lower values meaning less. Therefore, if we compute the
cosine similarity between the query vector and all the document
vectors, sort them in descending order, and select the documents with
top similarity, we will obtain an ordered list of relevant documents
to this query.
Jaccard coeffecient and implementation
The Jaccard index, also known as the Jaccard similarity coefficient , is a statistic used for comparing the similarity and diversity of sample sets.
The Jaccard coefficient measures similarity between sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets:
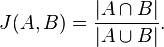
- Here is the simple implementation of jaccard coeffecient using java.
- --------------------------------------------------------------------
- import java.awt.List;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Scanner;
class jaccard {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.println("Enter 1st word ");
String s1=scan.next();
System.out.println("Enter 2nd word ");
String s2=scan.next();
jaccard_coeffecient(s1,s2);
}
private static void jaccard_coeffecient(String s1, String s2) {
double j_coeffecient;
ArrayList<String> j1 = new ArrayList<String>();
ArrayList<String> j2 = new ArrayList<String>();
HashSet<String> set1 = new HashSet<String>();
HashSet<String> set2 = new HashSet<String>();
s1="$"+s1+"$";
s2="$"+s2+"$";
int j=0;
int i=3;
while(i<=s1.length())
{
j1.add(s1.substring(j, i));
j++;
i++;
}
j=0;
i=3;
while(i<=s2.length())
{
j2.add(s2.substring(j, i));
j++;
i++;
}
Iterator<String> itr1 = j1.iterator();
while (itr1.hasNext()) {
String element = itr1.next();
System.out.print(element + " ");
}
System.out.println();
Iterator<String> itr2 = j2.iterator();
while (itr2.hasNext()) {
String element = itr2.next();
System.out.print(element + " ");
}
System.out.println();
set2.addAll(j2);
set2.addAll(j1);
set1.addAll(j1);
set1.retainAll(j2);
System.out.println("Union="+set2.size());
System.out.println("Intersection="+set1.size());
j_coeffecient=((double)set1.size())/((double)set2.size());
System.out.println("Jaccard coeffecient="+j_coeffecient);
}
}
Subscribe to:
Posts (Atom)